
Think about trying to find something from a book without looking the table of contents. This is what SQL server does as a standard with a table which does not have indexes.
What
In this post, I show how to make a clustered and non-clustered index to a table to reduce the query time of a window function up to 4 times. I make a performance comparison of these methods too.
Baseline
We have the following query, creating temp_test_table. As a standard customer_event_table does not have any index, with 35 million rows.
SELECT customer_number ,month_id ,change ,SUM(change) OVER (PARTITION BY customer_number ORDER BY month_id) AS phase INTO temp_test_table FROM customer_event_table
Here “change” can have a value of 0 or 1, and we want to track when changes occur during the lifetime of a customer (over month_id values).
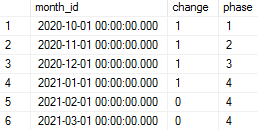
An example result for one customer could be:
Clustered index
A table can only have one clustered index. This is the order in which data is physically stored in a table. Usually this is the primary key of a table. Most of the time changing the physical index is not feasible as the primary key is used for the data model structure. However, for some analytical tables or temp tables this is possible. Clustered index sorts a table, it does not consume extra storage.
Here I make a clustered index to improve the performance of the window function presented in the baseline section:
CREATE CLUSTERED INDEX INDEX_for_window_function ON temp_test_table (customer_number, month_id)
The index creation took 25 seconds. The index is added to the columns which are used in the window function in the PARTITION BY and ORDER BY structures (customer_number, month_id).
Non-clustered index
As explained by sqlshack.com: “A non-clustered index doesn’t sort the physical data inside the table. In fact, a non-clustered index is stored at one place and table data is stored in another place. Inside the non-clustered index data is stored in the specified order. The index contains column values on which the index is created and the address of the record that the column value belongs to.” There can be multiple non-clustered indexes on a single table. Non-clustered indexes consume storage space. Furthermore, if any update or other modifications are done to a table, the more there are non-clustered indexes the more modification operations slow down. Obviously, with our temp table, these modifications are not a challenge.
CREATE NONCLUSTERED INDEX INDEX_for_window_function ON temp_test_table (customer_number, month_id) INCLUDE (change)
The index creation takes 15 seconds. It is possible to use INCLUDE option with NONCLUSTERED INDEX . INCLUDE can have the other columns of the select to speed up the lookup. As written by mssqltips.com: “There are a couple benefits to using included columns. First it gives you the ability to include columns types that are not allowed as index keys in your index. Also, when all the columns in your query are either an index key or included column, the query no longer has to do an extra lookup in order to get all the data needed to satisfy the query which results in fewer disk operations.” However, consider that too many columns in an index can reduce the caching efficiency which can reduce the query performance. This is especially the case if a column in an index is not actually needed for a query to look up data.
Performance comparison
The results are in the order from the worst to the best in the terms of the query time. Interestingly, clustered index vs non-clustered index requires a lot of read-ahead reads which is good for the CPU time but not good for the total query time.
4. No index
Table ‘customer_event_table’. Scan count 5, logical reads 324 756, physical reads 0, read-ahead reads 0
CPU time = 461236 ms, elapsed time = 401 041 ms.
3. Clustered index
Table ‘customer_event_table’. Scan count 5, logical reads 338 796, physical reads 330, read-ahead reads 335 627
CPU time = 411984 ms, elapsed time = 380 812 ms.
2. Non-clustered index with include
Table ‘customer_event_table’. Scan count 5, logical reads 36 062 454, physical reads 0, read-ahead reads 31
CPU time = 444047 ms, elapsed time = 179 210 ms.
1. Non-clustered index without include
Table ‘customer_event_table’. Scan count 5, logical reads 35 864 147, physical reads 0, read-ahead reads 17
CPU time = 423374 ms, elapsed time = 141 640 ms.
Conclusion
To improve the query time of a window function in SQL try to use a non-clustered index to the columns which are used in the window function in the PARTITION BY and ORDER BY structures.
For more SQL tricks, see SQL How to Forecast with Linear Regression