Azure Synapse serverless on-demand SQL is easy to use and makes fast big data analytics available to everyone who knows SQL. However, there are a couple of optimization actions which significantly reduces the SQL query time. The actions include both the query syntax itself and how the queried data is stored and organized in a data lake.

What
Here is a top 5 list to consider in speeding up Synapse serverless SQL queries:
- Parquet. Read parquet files.
- File size and partitioning. Keep the size of a single file (partition) between 200 MB and 3 GB. Optimize the partitioning of parquet files when possible.
- Data types definition.
- Folder structures. Save data to a folder structure and use file metadata in queries.
- External tables. Use CETAS (CREATE EXTERNAL TABLE AS SELECT) when the query is repeated or used in a chain with other queries.
For a more extensive optimization guide, refer to Microsoft Documentation: Best practices for serverless SQL pool in Azure Synapse Analytics
Why
1. Parquet
Parquet file format uses column-wise compression. It is efficient and saves storage space. Queries that fetch specific column values need not read the entire row data thus improving performance. As an example, a time series data of 90 GB stored in hundreds of thousands of csv files can fit to 5 GB as an optimally partitioned parquet. Furthermore, it is possible to define the data types for columns as a file metadata, meaning data is in the correct format for SQL queries. Parquet is a widely used data format in data storage and data engineering, across multiple cloud platforms and technologies.
2. File size and partitioning
When querying parquet with serverless SQL, the metadata related to the partitioning of the parquet is utilized for faster query execution. For example, with time series data, if the partitioning is done on repeating date values, it will be multiple times quicker to find all the data related to a selected date with the optimized partitioning compared to no partitioning. However, as pointed out by DZone, we should partition a parquet file only on the columns to which the data is likely to be queried against. The query times are substantially larger if there is a need to query against another column.
Furthermore, the partitioning significantly reduces file size. The earlier example of 90 GB of time series data takes 20 GB as a single parquet file, or partition. With dynamic range partitioning to 200 MB partitions, only 5 GB is required. It goes without saying that if there are too many small files, like tens of thousands, performance is a lot weaker than with any file append or partitioning strategy.
The downfall of optimized data partitioning is the management of it. Update: I discuss this more in my post Data Lake VS Delta Lake – Data Upsert and Partition Compaction Management. In the post I explain how delta lake automates and standardizes a lot of the big data management listed in this blog post compared to a standard data lake. Another great reason to use delta lake and for example Databrics is that despite all the optimization covered in this blog post, Synapse serverless SQL can now and then still throw an annoying error “This query cannot be executed due to current resource constraints.” This is not really nice in a production environment.
3. Data types definition
When writing serverless SQL select query from datalake, define data types using WITH block. If you do not, all your character columns will be automatically set to VARCHAR(8000) which makes queries multiple times slower, or not even executing due to “This query cannot be executed due to current resource constraints.”
4. Folder structures
It is possible to utilize the folder structure of a data lake in serverless SQL queries. As an example, in the WHERE clause and in the GROUP BY clause can be mentioned a folder name like “2019”. If data has clear time dependency or categories, it makes sense to think about storing it to a simple folder structure. The impact to query speed is the more significant the more there is data.
5. External tables
Once an external table is created and stored to data lake, it is fast to query. Depending on the data and task, the experience is like with SQL server tables on calculation jobs.
The creation of an external table works as fast as a select statement for hundreds of thousands, potentially a couple of millions of rows. However, running a calculation chain including the creation of an external table for hundreds of millions of rows is likely slower than using only CTEs in a chain which filter and group the data.
Inserts or updates are not possible to external tables. One needs to drop the existing external table to create a new one with the same name.
How
2. Optimizing file size and partitioning
See this official Azure Data Factory (almost the same as Synapse Pipeline dataflow) YouTube tutorial (link) on how to turn single csv files to parquet.
In the tutorial, the partitioning of the data is not covered. This happens under the optimization tab. See the picture below. Furthermore, leave under Settings tab –> File name to default. Basically, the data entity is the folder itself and the Synapse dataflow activity takes care of the naming of the single partitions (files) in the data entity (folder).
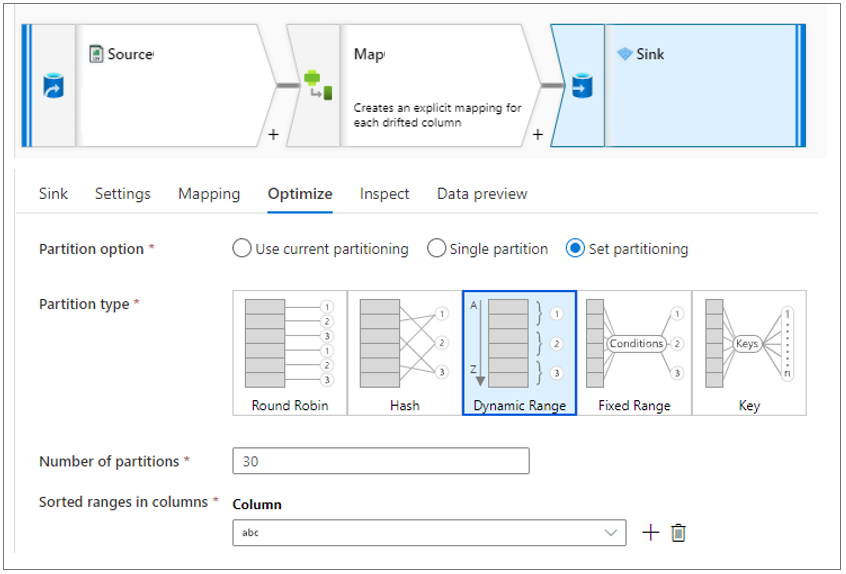
There are five partitioning options:
- Round Robin. Simple distribution of data across partitions equally. Use this partitioning when not having a good key candidate for partitioning.
- Hash. The columns (or computed) value is used to form a uniform hash to distribute values. Rows with similar values are assured to fall in the same partition.
- Dynamic Range. Dynamic range is similar to Fixed except that system figures out the ranges for the columns (or computed) columns you supply.
- Fixed Range. Fixed Range partitioning will allow you set ranges for your key values to provide balanced partitions. Only use this option if you have an understanding of the range of values of your data.
- Key. Every distinct Column (no computed columns) value becomes a new partition. Use this partitioning if the number of distinct values are not huge.
Key partitioning is useful in the sense that the number of partitions can change according to the amount of data. This is good with for example a time series data with similar distribution of the data quantity for each date key value.
Dynamic range requires the definition of the number or partitions, but can automatically consider that there are more observations in a selected column value than in another.
Hash is potential candidate if there is an idea of a key column and the other partitioning strategies do not fit.
Round Robin is likely better than no partitioning optimization of a parquet data entity, at least for querying the data.
3.Data types definition
See the example from the Microsoft documentation of the WITH(…) structure:
SELECT
vendorID, tpepPickupDateTime, passengerCount
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=2018/puMonth=*/*.snappy.parquet',
FORMAT='PARQUET'
)
WITH (
vendor_id varchar(4), -- we used length of 4 instead of the inferred 8000
pickup_datetime datetime2,
passenger_count int
) AS nyc;
4. Querying folder structures
Documentation by Microsoft is clear and easy to apply: Use file metadata in serverless SQL pool queries
5. Creating external tables
Microsoft Documentation is clear and easy to apply: Store query results to storage using serverless SQL pool in Azure Synapse Analytics. Usually, a database and a data source are available in a configured cloud environment, but an external file format needs to be created before an external table!