Data warehouse, data lake and delta lake data platform architectures behave differently in the terms of data upserts or merge, and file partition compaction management. Big data often requires inserts, updates, or other incremental data loads. File compaction management is required to speed up the querying of the data for machine learning, analytics, and reporting.

Different data platform architectures
A data warehouse with relational databases is great for accurate and standardized reporting with a proven concept and history spanning multiple decades. However, the amount of data and the variety of it is growing – meaning tools like data lakes and delta lakes come in handy.
Databrics suggests in their publication Lakehouse A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics that data warehouse is not even needed in the future due to the advantages of delta lake and their Databrics platform with an optimized version of the open-source delta lake. You can read a different opinion from James Serra (Data Platform Architecture Lead at EY): Data Lakehouse defined or Data Lakehouse & Synapse. In addition, Inderjit Rana (Microsoft Senior Cloud Architect) shares his views on different architectures in his post: Data Lake or Data Warehouse or a Combination of Both — Choices in Azure and Azure Synapse.
Below is an overview picture of the different data platform architectures from the above mentioned Databrics Lakehouse publication. I have clarified it with pointing out where upserts and data partition compaction occur in each architecture (A, B, C) for this blog post. Upsert, or insert and update, is one of the key concepts in managing data in a data platform. Big data often requires inserts, updates, or other incremental changes. File partition compaction management is required to speed up the querying of the data for machine learning, analytics, and reporting.
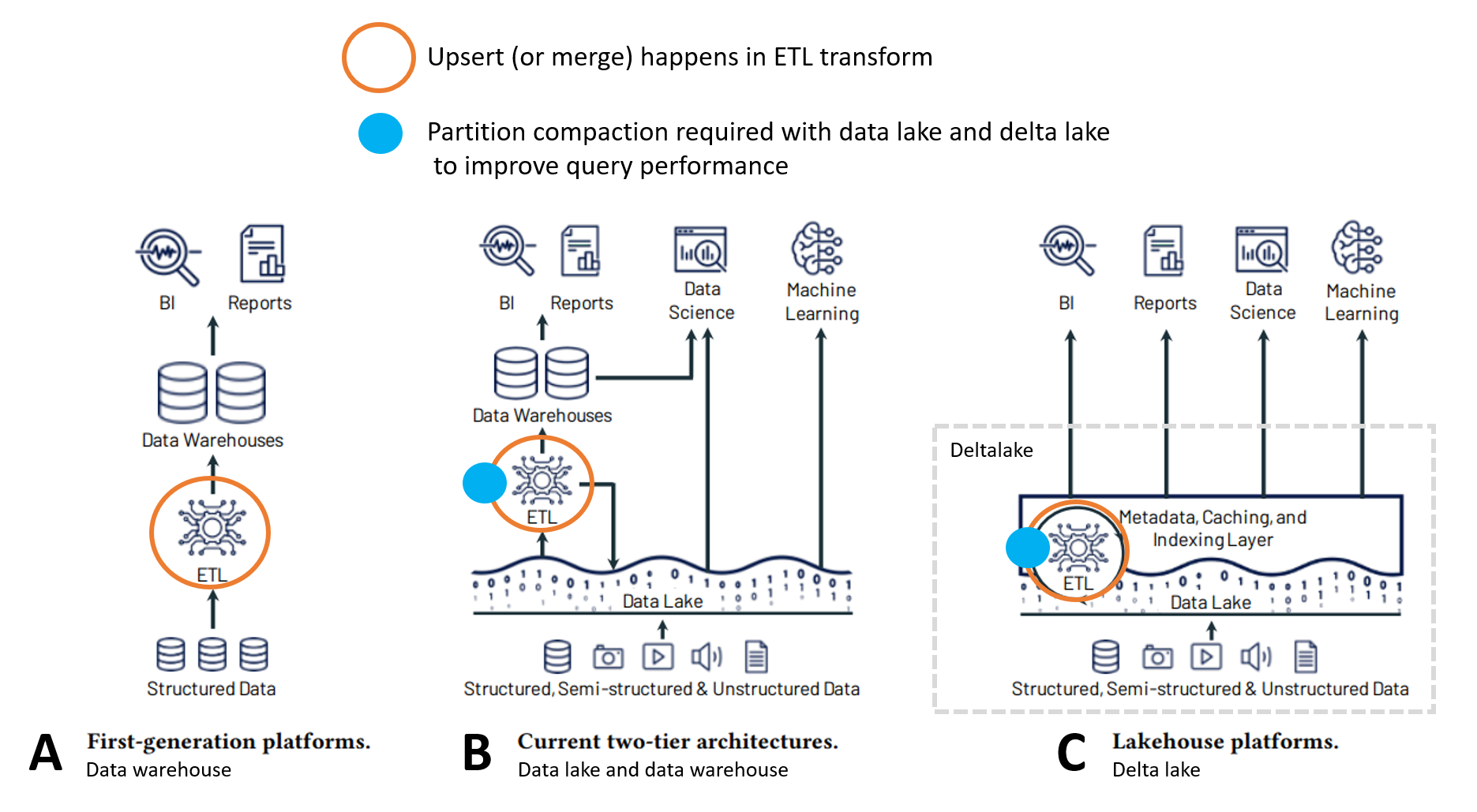
Upsert or merge
Upsert is a combination of update and insert. When source data changes the changes need to happen in a data platform too. Typically, this is achieved with upsert and conditional delete statements in incremental data loads. The more there is data the more likely full data loads are not possible, and the more often incremental data loads need to occur. Incremental data loads save the history too, depending on the potential delete practices.
In architecture A, SQL data warehouse supports upsert (merge) or insert and update with a simple MERGE command.
In architecture B, an upsert is done to a data warehouse based on the data in a data lake. It is not that easy to incrementally load data from a data lake to a data warehouse for example with Microsoft Azure Data Factory, see an example. It is easier to load the new data to a staging table in the data warehouse and perform upsert with the SQL server MERGE command. A standard data lake does not support update or insert statements.
In architecture C, delta lake supports as a standard upserts and conditional deletes. It is basically as simple as with SQL server, see for example Databrics documentation examples. The downfall is that if one wants to push all the changes to a SQL data warehouse it is not that easy or reliable as a standard at the moment. There are some relatively easy to use custom functions like the one described in this blog post.
Partition compaction
In architecture C, delta lake upsert operations lead to a lot of small files which form a delta table or data entity. The operation to combine these small files to larger partitions is called compaction. It is one of the delta lake best practices listed by Databrics documentation.
Databrics version of delta lake supports auto compaction as a part of upsert or merge command parameters. Furthermore, Databrics delta lake supports the manual compaction of existing data. With the open-source delta lake, partition compaction means overwriting the data again to the delta lake for the partitions which are combined. See an example and further discussion here.
In architecture A in a data warehouse data compaction is not possible. In general, data is not compressed to columnar storage format like with parquet files in data lake or in delta lake tables.
As an example of architecture B, Azure Data Lake Gen2 supports data partition optimization or in other words compaction with parquet data type. However, it is not possible or easy to just edit a selected partitioning. Typically, the data for which the partitioning needs to be compacted is written again to the data lake. This can be a manual maintenance job for some old historical data or a part of a data transformation pipeline. As an example, the result can be that for a selected folder like “year_2019” the data partitioning is optimized for querying. See my blog post Azure Synapse Serverless SQL Optimization with Examples for more detailed guide to data lake storage and query speed optimization.
Conclusion
Delta lake, and especially Databrics delta lake architecture, make big data analytics and machine learning data pipelines easier to build and reliably maintain than with traditional data lake architecture. On the other hand, as an example for standardized financial reporting, delta lake can be somewhat complicated and new technology compared to SQL data warehouse. For the moment being, integrating delta lake and SQL data warehouse is unfortunately not as easy and fast as it should be. It makes sense to consider making a lot of the analytics ELT pipelines with Databrics and not using a traditional SQL data warehouse. In this blog post, only data partition compaction and upserts were covered. There are many other concepts and features to consider in building data architectures. Here are a couple of interesting links:
Azure Synapse Serverless vs Databricks SQL Analytics Benchmark
Databrics, Announcing Databricks Serverless SQL
Databrics, How We Achieved High-bandwidth Connectivity With BI Tools
Microsoft SQL Server vs. Spark SQL